Author: Ofir Nabati
This post summarizes the work Online Limited Memory Neural-Linear Bandits with Likelihood Matching, accepted to ICML 2021. The code is available here.
Joint work with Tom Zahavy and Shie Mannor.
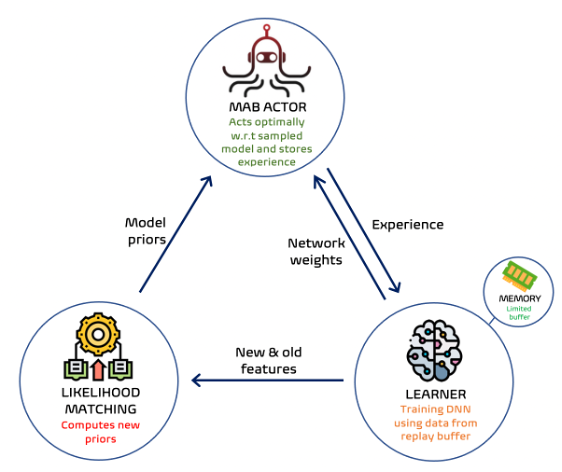
We propose a new neural linear bandit algorithm; it uses a deep neural network as a function approximator while exploration is based on linear contextual bandit, using the network’s last layer activations as features. Our main contribution is a mechanism called likelihood matching for dealing with the drift that occurs to these features through training, under finite memory constraints. The basic idea of likelihood matching is to compute new priors of the reward using the statistics of the old representation whenever a change occurs. We call our algorithm NeuralLinear-LiM2 or LiM2 in short.
Background
Exploration with Neural Networks
Using neural networks in reinforcement learning enables the agent to generalize across states and learn rich domain representations. Nevertheless, the question of how to perform efficient exploration during the representation learning of deep models still poses an open problem.
Many works have tried to tackle it, to name a few: Neural Greedy, variational inference [8], dropout [9], Monte Carlo methods [10], bootstrapping [11], direct noise injection [12], NTK methods [6,7] and Neural Linear [1].
Our focus is on Neural Linear method, in which the exploration is done on top of the last layer of a neural network and have shown to achieve the best results among a long list of algorithms.
LiM2 has the same superior performance of Neural Linear but under memory constraints.
Linear Bandits
In contextual multi-armed bandits problem, at each round the agent observes a context b(t), chooses an action a(t) out of N possible actions and receives a reward r(t).
The goal of our agent is to maximize the total reward over T rounds.
Linear bandits is a special case of contextual bandits problem in which the expected reward is a linear function of the context and an (unknown) fixed parameter. More formally:
![]()

Thompson Sampling
One of the most famous algorithms that is known to achieve excellent results on linear bandits is Thompson Sampling (TS) [3,4]. TS balances between exploration and exploitation by sampling the model (i.e. the reward parameter) at each round from the posterior and acts optimaly w.r.t it.
The detailed TS algorithm with Gaussian likelihood:

Note the prior of the covariance matrix, is fixed. Also, the mean prior is fixed to 0 and therefore omitted from the text.
Neural-Linear Bandits
In real life, the rewards are rarely act as a linear function. On the other hand, former methods the utilizes neural networks for exploration suffer from inefficient exploration [1,5].
Therefore, Riquelme et al. proposed a state-of-the-art method called neural linear bandits [1] that learn a linear exploration policy on top of the last hidden layer of a neural network. In their work, they assume that the reward acts lineary w.r.t this deep features.
The network is trained in phases to predict the rewards using experience from an unlimited memory. Every time the representation is changed (a.k.a representation drift), the posterior parameters need to be recomputed under the new representation:
![]()
Like Linear TS, in this method the posterior priors are also fixed.
Catastrophic Forgetting

The main drawback of neural-linear bandits is the necessity to store the entire history, not to mention the growing computational burden of the statistics. This makes the algorithm infeasible for long horizon scenarios.
Unfortunately, when memory size is limited, the parameters are recomputed with partial information, which causes performence degradation. This phenomeman is known as catastrophic forgetting [2].
Our Method: Limited Memory Neural Linear with Likelihood Matching (LiM2)
The rising question is how to solve representation drift without suffering from catastrophic forgetting?
Likelihood Matching
We want to preserve past information before the network update. We do this by storing this past information at the new priors under the new representation.
This is done by applying a method called likelihood matching. We assume that the likelihoods of the reward before and after the representation update are close under the neural linear assumption:
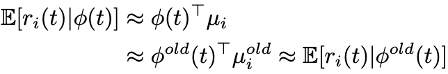
which means we can compare their mean and variance. It comes out that the variance of the reward (for specific context) under the estimated model parameters is:
![]()
We wish to find new posterior priors s.t for every context at our memory there will be varaince matching and mean matching:
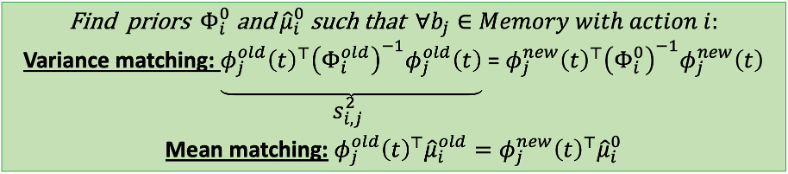
The likelihood matching is done by solving semidefinite programming problem for the covariance matrix:

where Xij is an outer product of Φj under the new representation. Also, it turns out that the weights of the last layer of the network makes a very good prior for the mean.
Solving the SDP:
Solving SDP is computationally prohibitive in general. Therefore, we solve the SDP by applying stochastic gradient decent (SGD) using sampled batches from the replay buffer.
Each SGD iteration is followed by eigenvalues thresholding to project the covariance matrix back to PSD matrices space.
Online mode:
We take advantage of the iterative learning of the DNN and the iterative nature of the SGD by using the same batch to update the DNN weights and the covariance simultaneously.
Applying SGD in parallel to the DNN update iterations is sample efficient due to the reuse of the same batch for both tasks.
We noticed that using only a single update iteration for both the DNN and likelihood matching is enough to get competitive results and enables LiM2 to operate completely online.
Results
We compare LiM2 against the next methods:
- Neural-linear with unlimited memory (NeuralLinear)
- Limited memory without likelihood matching (NeuralLinear-Naive).
- Also, we compare our method against Neural Tangent Kernel (NTK) based methods [6,7], which assumes negligible representation drift under NTK assumptions (for more information we refer the reader to the paper) (NeuralTS and NeuralUCB).
- An ablative version which only compute the prior for the mean (NeuralLinear-MM).
- Linear TS, which uses the raw contexts as the features.
For more details regarding our experiments, we refer the reader to the paper.
Catastrophic forgetting
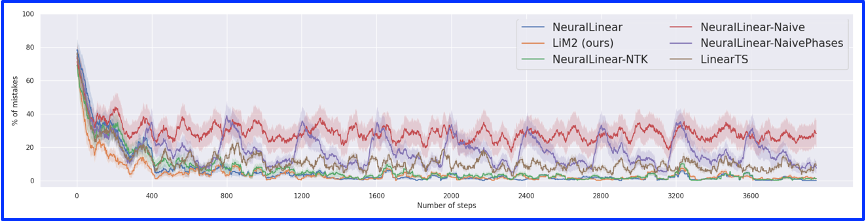
We examine the impact of catastrophic forgetting on the algorithm’s performance. We add aversion of NeuralLinear-Naive in which the training is done in phases of 400 steps, similar to the limited-memory variation in [1].
The figure bellow presents the performance for each round. As can be noted, methods with limited memory and no likelihood matching suffer from catastrophic forgetting – the online naive method stays high all the time while the naive, trained in phases version, peaks every time the network is trained (marked in red arrows).
On the other hand, LiM2 maintains a low error rate like the unlimited memory version.
Memory size
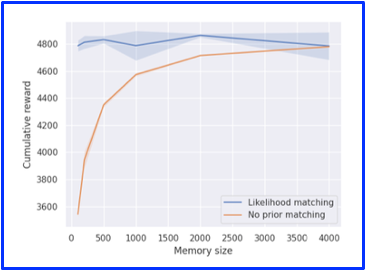
In order to emphasize the robustness of LiM2 for various memory sizes, we compare It against limited memory neural-linear without likelihood matching (right figure). As can be noted, LiM2 performance does not degrade even when the memory size is extremely low as opposed to the regular method.
Operating online enables LiM2 to use a memory with a similar size of the batch size. Therefore, LiM2 is robust to any memory size bigger than the batch size.
Real world data
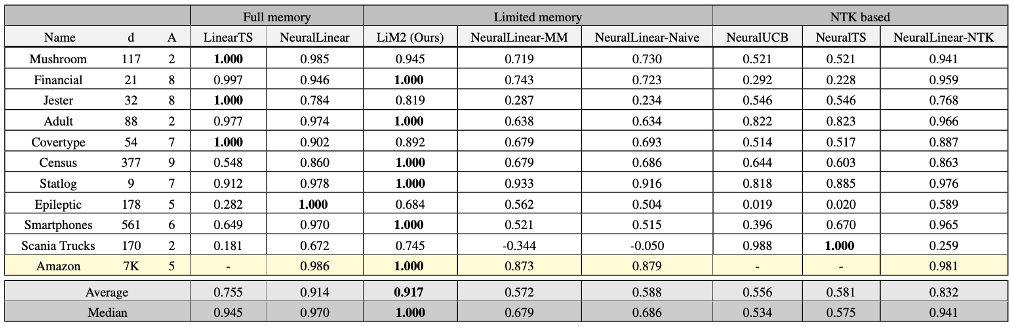
We evaluate LiM2 and baselines on ten real-world datasets. The results are in Table below. LiM2 clearly improves the performance of the limited memory neural-linear variations without likelihood matching and has comparable performance to the unlimited memory version (NeuralLinear).
Conclusions
- In order to use limited memory without suffering from catasrophic forgeting – LiM2 provides a good robust solution.
- LiM2 exihibits comparable performance to neural linear with unlimited memory without significant additional computional burden.
- LiM2 enables to operate onlie in the sense it compute one update and likelihood matching iteraion each round and not in phases as the former method.
Bibliography
- Riquelme, C., Tucker, G., and Snoek, J. “Deep bayesian bandits showdown.” International Conference on Learning Representations, 2018.
- Kirkpatrick, James, et al. “Overcoming catastrophic forgetting in neural networks.”Proceedings of the national academy of sciences 114.13 (2017): 3521-3526.
- Thompson, William R. “On the likelihood that one unknown probability exceeds another in view of the evidence of two samples.” Biometrika 25.3/4 (1933): 285-294.
- Agrawal, Shipra, and Navin Goyal. “Thompson sampling for contextual bandits with linear payoffs.” International Conference on Machine Learning. PMLR, 2013.
- Osband, Ian, John Aslanides, and Albin Cassirer. “Randomized prior functions for deep reinforcement learning.” Advances in Neural Information Processing Systems, 2018.
- Zhou, Dongruo, Lihong Li, and Quanquan Gu. “Neural contextual bandits with UCB-based exploration.” International Conference on Machine Learning. PMLR, 2020.
- Zhang, Weitong, et al. “Neural Thompson Sampling.” arXiv preprint arXiv:2010.00827 (2020).
- Blundell, Charles, Cornebise, Julien, Kavukcuoglu, Koray, and Wierstra, Daan. “Weight uncertainty in neural network”. In International Conference on Machine Learning, pp. 1613–1622, 2015.
- Gal, Yarin and Ghahramani, Zoubin. “Dropout as a bayesian approximation: Representing model uncertainty in deep learning”. In International conference on machine learning, pp. 1050–1059, 2016.
- Mandt, Stephan, Hoffman, Matthew D., and Blei, David M. “A variational analysis of stochastic gradient algorithms”. In International Conference on Machine Learning, 2016.
- Efron, Bradley. “The jackknife, the bootstrap and other resampling plans”. SIAM, 1982.
- Plappert, Matthias, et al. “Parameter space noise for exploration.” arXiv preprint arXiv:1706.01905 (2017).
Algorithms

