Author: Ofir Nabati
This post summarizes the work Online Limited Memory Neural-Linear Bandits with Likelihood Matching, accepted to ICML 2021. The code is available here.
Joint work with Tom Zahavy and Shie Mannor.
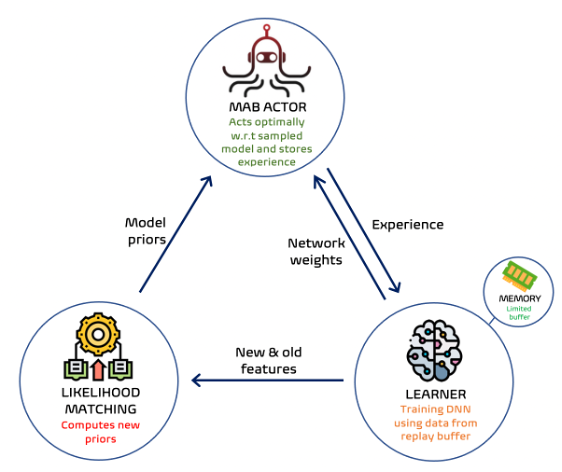
We propose a new neural linear bandit algorithm; it uses a deep neural network as a function approximator while exploration is based on linear contextual bandit, using the network’s last layer activations as features. Our main contribution is a mechanism called likelihood matching for dealing with the drift that occurs to these features through training, under finite memory constraints. The basic idea of likelihood matching is to compute new priors of the reward using the statistics of the old representation whenever a change occurs. We call our algorithm NeuralLinear-LiM2 or LiM2 in short.
Continue Reading Online Limited Memory Neural-Linear Bandits with Likelihood Matching