Chen Tessler*, Guy Tennenholtz* and Shie Mannor
Published at NeurIPS 2019
Paper, Code
What?
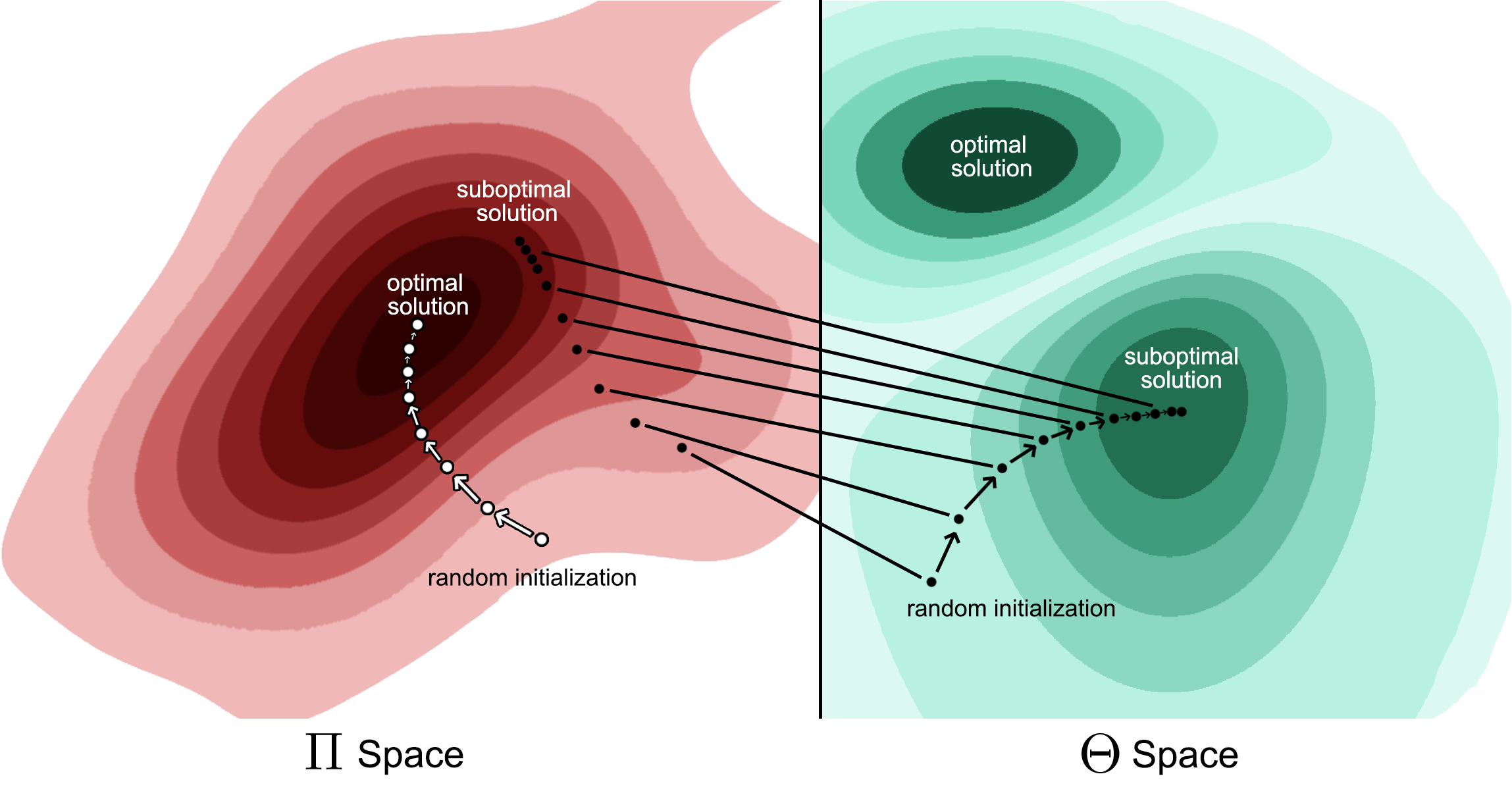
We propose a new optimization framework, named Distributional Policy Optimization (DPO), which optimizes a distributional loss (as opposed to the standard policy gradient).
As opposed to Policy Gradient methods, DPO is not limited to parametric distribution functions (such as Gaussian and Delta distributions) and can thus cope with non-convex returns
Author: Chen Tessler @tesslerc
Continue Reading Distributional Policy Optimization: An Alternative Approach for Continuous Control